테크 & 도구
SEC EDGAR 2026: 주식 리서치 전 출처 고정
AI 보조 주식 리서치를 발행 가능한 분석으로 바꾸기 전에 회사, 공시 유형, 기간, 첨부 문서, 정확한 표와 XBRL 데이터 경계를 고정하는 2026년 워크플로입니다.
핵심 논지
(Source: SEC EDGAR Search and Access)
AI 도구는 회사를 빠르게 요약할 수 있습니다. 하지만 주식 리서치의 첫 질문은 요약문이 그럴듯한지가 아닙니다. 실제 공시가 있는지, 기간이 맞는지, 숫자가 2차 설명이 아니라 회사 문서에서 왔는지를 먼저 확인해야 합니다.
함께 읽을 글: ChatGPT·Gemini·Claude 2026: 주식 주장 전 근거 규율 | 연준 금리 전망 2026: 인하 전 데이터 트리거 | 미국 주식 투자 2026: 종목 선택 전 증권사 점검
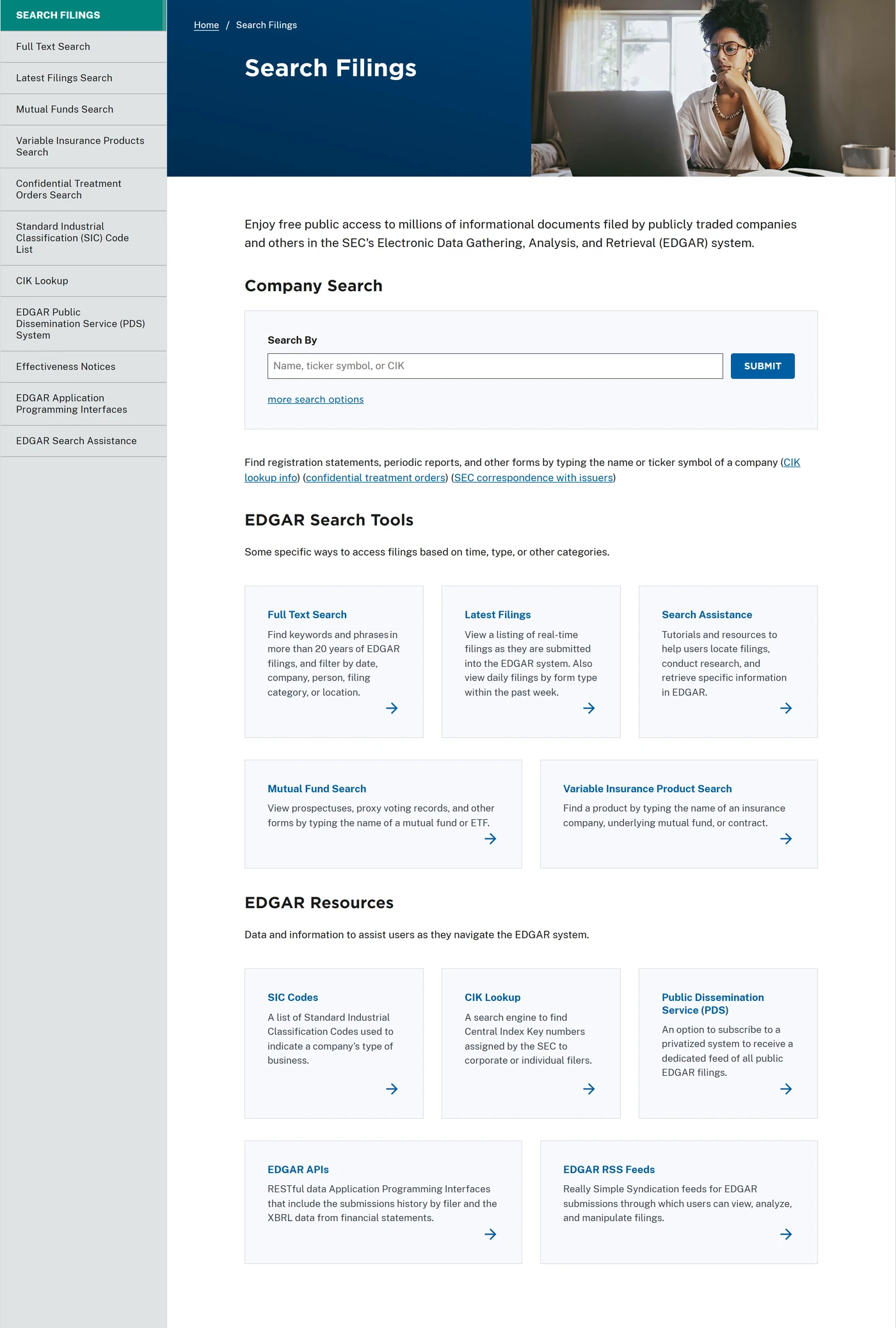
그래서 미국 상장사 리서치에서는 SEC EDGAR가 워크플로의 앞단에 있어야 합니다. EDGAR에는 연차보고서, 분기보고서, 8-K, 증권신고서, 위임장, 첨부 문서가 공개 기록으로 쌓입니다. 시장이 읽는 서사는 이 기록 위에 올라가야 합니다.
실전 규칙은 단순합니다. 먼저 공시 증거를 고정하고, 그다음에 해석을 씁니다. AI 모델은 그 이후에 자료 정리와 문장 구조화를 도울 수 있지만, 어떤 공시가 기준인지 결정하는 역할을 대신해서는 안 됩니다.
1차 출처 스냅샷
위의 SEC 검색 페이지는 올바른 회사와 공시를 찾는 출발점입니다. 아래 API 캡처는 제출 이력과 XBRL company facts라는 구조화 데이터 경계를 고정합니다. 검색 화면과 API 문서는 서로 다른 역할을 하므로 같은 캡처를 반복하지 않고 분리해 읽어야 합니다.
 Source capture: SEC EDGAR Application Programming Interfaces, captured 2026-05-21. 제출 이력 데이터와 XBRL company facts 데이터가 분리되어 있어, 공시 기반 스크리닝의 구조화된 원천을 확인할 수 있습니다.
Source capture: SEC EDGAR Application Programming Interfaces, captured 2026-05-21. 제출 이력 데이터와 XBRL company facts 데이터가 분리되어 있어, 공시 기반 스크리닝의 구조화된 원천을 확인할 수 있습니다.
이 두 공식 페이지는 워크플로의 경계를 정합니다. 검색 페이지는 올바른 회사와 공시를 찾는 곳이고, API 문서는 어떤 구조화 데이터가 SEC에서 직접 제공되는지 확인하는 곳입니다.
주식 리서치에서 EDGAR는 나중에 붙이는 출처가 아니라, 서사를 쓰기 전 통과해야 하는 출처 고정 장치입니다. 초안을 먼저 만들고 나중에 그 초안에 맞는 공시를 찾는 방식은 순서가 거꾸로입니다.
예외는 있습니다. 대상 회사가 SEC 공시 체계 밖에 있거나, 핵심 사실이 회사 공시가 아닌 경우입니다. 해외 상장사, 비상장사, 원자재 데이터, 중앙은행 지표, 정부 통계는 거래소, 중앙은행, 정부기관, 발행사 공식 페이지가 1차 출처가 될 수 있습니다. 그래도 원칙은 같습니다. 출처가 먼저이고, 서사는 그다음입니다.
EDGAR 실전 4단계
1. 회사를 고정한다
SEC Search Filings에서 회사명, 티커, CIK로 회사를 찾습니다. 티커는 바뀔 수 있고, 회사는 분할될 수 있으며, 비슷한 이름의 등록 법인이 여러 개일 수 있습니다. CIK는 SEC 공시에서 회사를 식별하는 안정적인 기준입니다.
첫 질문은 "주가가 어떻게 움직였나"가 아니라 "이 문서를 제출한 법인이 누구인가"입니다. 지주회사 구조, ADR, IPO 직후 기업, 사명 변경 기업을 볼 때 이 확인은 특히 중요합니다.
2. 공시 유형을 고정한다
공시 유형에 따라 증거의 무게가 달라집니다. 10-K는 연간 감사 프레임입니다. 10-Q는 분기 업데이트입니다. 8-K는 실적 발표, 인수 계약, 경영진 변경, 부채 관련 문서 같은 이벤트성 첨부를 담을 수 있습니다. Proxy statement는 보상, 지배구조, 주주총회 안건을 확인하는 데 중요합니다.
안전한 메모는 form type과 filing date를 함께 적습니다. "최근 10-Q에 따르면"보다 "2026년 5월 2일 제출된 Form 10-Q에 따르면"이 검증하기 쉽고 오용 가능성이 낮습니다.
3. 기간을 고정한다
많은 리서치 오류는 기간 오류입니다. 매출은 분기, 최근 12개월, 회계연도, 캘린더 연도, 세그먼트 기준일 수 있습니다. 현금흐름은 이익과 다르게 움직일 수 있습니다. 주식 수는 basic, diluted, weighted-average, end-of-period 중 무엇인지에 따라 의미가 달라집니다.
숫자를 쓰기 전에는 세 가지를 확인해야 합니다.
- 이 숫자가 어떤 기간을 다루는가.
- 회사 전체 숫자인가, 특정 세그먼트 숫자인가.
- GAAP, non-GAAP, operating, adjusted, management-defined 중 무엇인가.
답이 불명확하면 그 숫자는 논지의 중심에 놓으면 안 됩니다.
4. 정확한 표나 첨부 문서를 고정한다
공시 목록 페이지 자체는 충분하지 않습니다. 실제 증거는 대개 표, footnote, risk factor, MD&A 문단, exhibit 안에 있습니다. 출판 가능한 근거 메모는 어느 영역이 주장을 지탱하는지 이름을 붙여야 합니다.
예를 들어 실적 관련 8-K에는 press-release exhibit이 붙고, 그 안에는 GAAP 표와 non-GAAP 표가 같이 있을 수 있습니다. 어떤 표를 쓰는지 적지 않으면 adjusted EBITDA, operating income, net income이 하나의 이야기로 섞일 수 있습니다.
EDGAR API는 어디에 쓰나
SEC API 문서는 EDGAR가 단순 검색 포털만은 아니라는 점을 보여줍니다. submissions endpoint는 CIK별 제출 이력을 보여주고, XBRL company facts는 공시의 구조화 항목을 제공합니다. 여러 기간을 비교하거나 반복 확인을 할 때 유용합니다.
API가 공시 읽기를 대체하지는 않습니다. 대신 전사 오류를 줄여 줍니다. XBRL 데이터에서 숫자를 가져오더라도 taxonomy label, 단위, 회계기간, 해당 개념이 실제로 논의하려는 지표와 맞는지를 다시 확인해야 합니다.
가장 가치 있는 용도는 자동 종목 추천이 아니라 감사 가능성입니다. 같은 쿼리를 다시 실행할 수 있고, SEC 데이터 표면으로 되돌아갈 수 있으며, 해석을 안정적인 출처에 묶어 둘 수 있습니다.
흔한 실수
첫 번째 실수는 티커만 믿는 것입니다. 티커는 편하지만 법인 식별자는 아닙니다. CIK 확인이 잘못된 회사의 공시를 인용하는 일을 막아 줍니다.
두 번째 실수는 exhibit drift입니다. 같은 분기를 press release, investor deck, 10-Q가 서로 다른 강조로 설명할 수 있습니다. 어떤 문서를 인용하는지 고정해야 합니다.
세 번째 실수는 non-GAAP 표현입니다. 조정 지표는 유용할 수 있지만 reconciliation 맥락이 필요합니다. 논지가 adjusted profitability에 기대고 있다면 그렇게 써야 합니다.
네 번째 실수는 AI 모델에게 "최신 숫자를 찾아줘"라고만 묻고 출처를 요구하지 않는 것입니다. 모델이 좋은 개요를 줄 수는 있지만, 출판 전에는 filing URL, filing date, table, period가 필요합니다.
발행 전 적용법
EDGAR 기반 메모는 길 필요가 없습니다. 다섯 가지 필드만 있으면 됩니다.
| 항목 | 최소 기준 |
|---|---|
| 회사 | 회사명과 CIK 또는 정확한 SEC 회사 페이지 |
| 공시 | Form type과 filing date |
| 증거 위치 | Exhibit, table, footnote, risk factor, MD&A 문단 |
| 기간 | 분기, 회계연도, 날짜 범위 |
| 주장 | 출처가 뒷받침하는 한 문장 |
이 다섯 가지가 있으면 AI 모델은 읽기 쉬운 설명으로 바꾸는 데 도움을 줄 수 있습니다. 이 필드가 없다면 모델은 분석이 아니라 신뢰를 대신 수행하게 됩니다.
결론
EDGAR는 법률가만 보는 데이터베이스가 아닙니다. 주식 리서치가 출처처럼 보이는 스토리텔링으로 흐르지 않게 막는 운영 체크포인트입니다.
근거 우선 발행 순서는 공시, 근거 메모, 논지, 리스크 점검, 초안입니다. 챗봇은 뒤의 세 단계를 도울 수 있지만, 앞의 두 단계를 대체해서는 안 됩니다. 공시가 있어야 리서치가 서사가 될 자격을 얻습니다.